数据库驱动
Go 官方提供了 database/sql 包来给用户进行和数据库打交道的工作,database/sql 库实际只提供了一套操作数据库的接口和规范,例如抽象好的 SQL 预处理(prepare),连接池管理,数据绑定,事务,错误处理等。官方并没有提供具体某种数据库驱动。
Tips:维护标准接口的好处是 —— 将数据库操作抽象出来,相当于同一份代码可用于多种数据库中,只需要换个驱动而已。比较常见的场景 —— 生产环境使用 MySQL / PostgreSQL 等专业数据库,测试时可使用速度更快的内存 SQLite 数据库。
引入驱动
通过go mod下载安装该MySQL驱动,命令如下:
$ go get github.com/go-sql-driver/mysql下载完成后要在项目中做匿名导入:
package main
import (
_ "github.com/go-sql-driver/mysql"
...省略代码...
)为什么需要匿名导入?
因为引入的是驱动,操作数据库时我们使用的是 sql 库里的方法,而不会具体使用到 go-sql-driver/mysql 包里的方法,当有未使用的包被引入时,Go 编译器会停止编译。为了让编译器能正常运行,需要使用 匿名导入 来加载。
当导入了一个数据库驱动后,此驱动会自行初始化(利用 init() 函数)并注册自己到 Golang 的 database/sql 上下文中。
Tips:Go 语言中,为了使用导入的程序包,必须首先对其进行初始化。初始化始终在单个线程中执行,并且以程序包依赖关系的顺序执行。初始化每个包后,会优先自动执行 init() 函数,并且执行优先级高于主函数的执行优先级。
连接数据库
// initDB 初始化数据库.
func initDB() {
var err error
config := mysql.Config{
User: "root",
Passwd: "FLHY1VJ0WEOBIG3N",
Addr: "127.0.0.1:3306",
Net: "tcp",
DBName: "goblog",
AllowNativePasswords: true,
}
// 设置数据库连接池
db, err = sql.Open("mysql", config.FormatDSN())
checkError(err)
// 设置最大连接数
db.SetMaxOpenConns(25)
// 设置最大空闲连接数
db.SetMaxIdleConns(25)
// 设置每个链接的过期时间
db.SetConnMaxLifetime(5 * time.Minute)
err = db.Ping()
checkError(err)
}
// checkError 检查数据库是否报错,如果有报错会将信息写进log.
func checkError(err error) {
if err != nil {
log.Fatal(err)
}
}
func main() {
initDB()
...代码省略...
}注意:上面代码当中,在 sql.Open() 的时候,并没有连接数据库,只是为连接数据库做好了准备。通常我们会再跟上一个 db.ping() 来检查连接的状态。
原生SQL
Exec
一般使用 sql.DB 中的 Exec() 来执行没有返回结果集的 SQL 语句(例如 INSERT, UPDATE, DELETE 等语句)。
语法如下:
func (db *DB) Exec(query string, args ...interface{}) (Result, error)参数为纯文本模式,不使用 Prepare,只发送一条 SQL 查询:
db.Exec("DELETE FROM articles WHERE id = " + strconv.FormatInt(a.ID, 10))多参数为 Prepare 模式,底层使用 Prepare 语句,会发送两条 SQL 查询:
query := "UPDATE articles SET title = ?, body = ? WHERE id = ?"
rs, err := db.Exec(query, title, body, id)返回的Result实现了 sql.Result 接口,代码如下:
type Result interface {
// 使用 INSERT 向数据插入记录,数据表有自增 id 时,该函数有返回值
LastInsertId() (int64, error)
// 表示影响的数据表行数
RowsAffected() (int64, error)
}对于INSERT, UPDATE, DELETE操作我们可以使用LastInsertId()方法或者RowsAffected()方法来判断SQL语句是否执行成功,对于其他类型的SQL语句我们直接判断返回的error即可。
QueryRow
一般情况下,我们使用 QueryRow() 来读取单条的数据。这是个可变参数的方法,具体语法如下:
func (db *DB) QueryRow(query string, args ...interface{}) *Row它的参数可以为一个或者多个。参数只有一个的情况下,我们称之为纯文本模式,多个参数的情况下称之为 Prepare 模式。之所以称之为 Prepare 模式是因为当多个参数的情况下,QueryRow() 封装了 Prepare 方法的调用,也就是说,下面这段代码:
err := db.QueryRow(query, id).Scan(&article.ID, &article.Title, &article.Body)等同于:
stmt, err := db.Prepare(query)
checkError(err)
defer stmt.Close()
err = stmt.QueryRow(id).Scan(&article.ID, &article.Title, &article.Body)使用 QueryRow() 的 Prepare 模式不仅保证了安全性,更能提升可读性。
注意:使用 Prepare 模式会发送两个 SQL 请求到 MySQL 服务器上,而纯文本模式只有一个。
Query
一般情况下,我们使用 Query() 从数据库中读取多条数据,而前面的 QueryRow() 是读取单条的数据。语法如下:
func (db *DB) Query(query string, args ...interface{}) (*Rows, error)调用方式与 QueryRow() 和 Exec() 一致,支持单一参数的纯文本模式,以及多个参数的 Prepare 模式。
Query() 和 Exec() 的区别在于Exec 只会返回插入的 ID 和影响行数,而 Query 会返回数据表里的内容(结果集),使用场景不同而已。
Scan方法
QueryRow() 会返回一个 sql.Row 结构体,通常我们使用链式调用的方式调用 sql.Row.Scan() 方法:
db.QueryRow(query, id).Scan(&article.ID, &article.Title, &article.Body)Scan() 将查询结果赋值到我们的 article struct 中,传参应与数据表字段的顺序保持一致。
需要注意的是,返回的 sql.Row 是个指针变量,保存有 SQL 连接。当调用 Scan() 时,就会将连接释放。所以在每次 QueryRow 后使用 Scan 是必须的。
sql.Rows 对象
sql.Rows包含的方法如下:
func (rs *Rows) Close() error //关闭结果集
func (rs *Rows) ColumnTypes() ([]*ColumnType, error) //返回数据表的列类型
func (rs *Rows) Columns() ([]string, error) //返回数据表列的名称
func (rs *Rows) Err() error // 错误集
func (rs *Rows) Next() bool // 游标,下一行
func (rs *Rows) Scan(dest ...interface{}) error // 扫描结构体
func (rs *Rows) NextResultSet() bool结果集在检出完 err 以后,遍历数据之前,应调用 defer rows.Close() 来关闭 SQL 连接。
一般我们会使用 rows.Next() 来遍历数据,如:
var articles []Article
//2. 循环读取结果
for rows.Next() {
var article Article
// 2.1 扫码每一行的结果并赋值到一个 article 对象中
err := rows.Scan(&article.ID, &article.Title, &article.Body)
checkError(err)
// 2.2 将 article 追加到 articles 的这个数组中
articles = append(articles, article)
}
// 2.3 检测循环时是否发生错误
err = rows.Err()
checkError(err)循环完毕需检测是否发生错误。
rows.Scan() 参数的顺序很重要,需要和查询的结果的 column 对应。
sql.Row 和 sql.Rows对象
QueryRow() 返回 Row 对象,这是基于 Rows 实现的。尽管在 Row 结构体当中含有一个 Rows 对象,但它最多只能存在一条数据:
type Row struct {
err error
rows *Rows
}而 Query() 则返回 sql.Rows 结构体,代表一个查询结果集,这里面包含从数据库里读取出来的(多条)数据和 SQL 连接:
type Rows struct {
dc *driverConn
releaseConn func(error)
rowsi driver.Rows
cancel func()
closeStmt *driverStmt
closemu sync.RWMutex
closed bool
lasterr error
lastcols []driver.Value
}Query() 与 sql.Rows 需要注意的点
- 在每一次 for rows.Next() 后,都记得要检测下是否有错误发生,调用 rows.Err() 可获取到错误;
- 使用 rows.Next() 遍历数据,遍历到最后内部遇到 EOF 错误,会自动调用 rows.Close() 将 SQL 连接关闭;
- 使用 rows.Next() 遍历时,如遇错误,SQL 连接也会自动关闭;
- rows.Close() 可调用多次,使用 rows.Close() 可保证 SQL 连接永远是关闭的。defer rows.Close() 需在检测 err 以后调用,否则会让运行时 panic ;
- 牢记在获取到结果集后,必须执行 defer rows.Close()。这样做能防止有时你在函数里过早 return ,或者其他操作忘记关闭资源,这是一个值得培养的良好习惯;
- 如果你在循环中执行 Query() 并获取 Rows 结果集,请不要使用 defer ,而是直接调用 rows.Close(),因为 defer 不会立刻执行,而是在函数执行结束后执行;
Prepare 和 Stmt
sql.DB.Prepare() 方法会返回一個 sql.Stmt 对象,与 Stmt 相关的方法如下:
stmt.Exec()
stmt.Query()
stmt.QueryRow()
stmt.Close()注意与 sql.DB 下的方法区分。
做单独的语句查询时,谨记调用 defer stmt.Close() 来关闭 SQL 连接。
使用 Prepare 语句会发送两次请求到数据库服务器上,第一次是调用 Prepare() 语句时,第二次是调用以上提到的四个 Stmt 方法时:
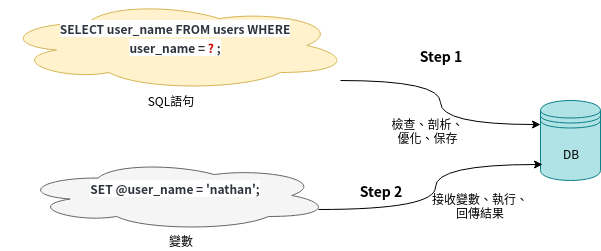
Prepare 语句可有效防范 SQL 注入攻击。
以下常见的 DB 查询方法中,调用在传参一个以上时,底层皆会使用 Prepare 来发送请求:
func (db *DB) Exec(query string, args ...interface{}) (Result, error)
func (db *DB) Query(query string, args ...interface{}) (*Rows, error)
func (db *DB) QueryRow(query string, args ...interface{}) *Rowsql.Tx 事务
使用以下可以开启事务:
func (db *DB) Begin() (*Tx, error)
func (db *DB) BeginTx(ctx context.Context, opts *TxOptions) (*Tx, error)Begin() 和 BeginTxt() 方法返回一个 sql.Tx 结构体,他支持以上提到的几种查询方法:
func (tx *Tx) Exec(query string, args ...interface{}) (Result, error)
func (tx *Tx) ExecContext(ctx context.Context, query string, args ...interface{}) (Result, error)
func (tx *Tx) Query(query string, args ...interface{}) (*Rows, error)
func (tx *Tx) QueryContext(ctx context.Context, query string, args ...interface{}) (*Rows, error)
func (tx *Tx) QueryRow(query string, args ...interface{}) *Row
func (tx *Tx) QueryRowContext(ctx context.Context, query string, args ...interface{}) *Row
// 预编译 Prepare
func (tx *Tx) Stmt(stmt *Stmt) *Stmt
func (tx *Tx) StmtContext(ctx context.Context, stmt *Stmt) *Stmt
func (tx *Tx) Prepare(query string) (*Stmt, error)
func (tx *Tx) PrepareContext(ctx context.Context, query string) (*Stmt, error)使用这同一个 sql.Tx 对数据库进行操作,就会在同一个事务中提交。
当使用 sql.Tx 的操作方式操作数据后,需要使用 sql.Tx 的 Commit() 方法提交事务,如果出错,则可以使用 sql.Tx 中的 Rollback() 方法回滚事务,保持数据的一致性,下面是这两个方法的定义:
func (tx *Tx) Commit() error
func (tx *Tx) Rollback() error例如:
func (s Service) DoSomething() (err error) {
// 1. 创建事务
tx, err := s.db.Begin()
if err != nil {
return
}
// 2. 如果请求失败,就回滚所有 SQL 操作,否则提交
// defer 会在当前方法的最后执行
defer func() {
if err != nil {
tx.Rollback()
return err
}
err = tx.Commit()
}()
// 3. 执行各种请求
if _, err = tx.Exec(...); err != nil {
return err
}
if _, err = tx.Exec(...); err != nil {
return err
}
// ...
return nil
}Demo
增加数据
先看代码:
// saveArticleToDB 向数据库中保存一篇文章,如果插入成功则返回一个主键ID.
func saveArticleToDB(title string, body string) (int64, error) {
// 变量初始化
var (
id int64
err error
rs sql.Result
stmt *sql.Stmt
)
// 1.获取一个 Prepare 声明语句
stmt, err = db.Prepare("INSERT INTO articles (title, body) VALUES (?, ?)")
if err != nil {
return 0, err
}
// 2.在此函数运行结束后关闭此语句,防止占用SQL连接
defer stmt.Close()
// 3.执行请求,传参进入绑定的内容
rs, err = stmt.Exec(title, body)
if err != nil {
return 0, err
}
// 4.插入成功的话,会返回自增的ID
if id, err = rs.LastInsertId(); id > 0 {
return id, err
}
return 0, err
}采用预编译的方式来规避SQL注入,代码详细解释如下:
- 先通过 db.Prepare() 来将SQL语句预编译,参数用 ? 进行占位
- 利用defer来延迟释放连接,避免长时间占用连接造成 ERROR 1040: Too many connections 错误
- Prepare 只会生产 stmt ,真正执行请求的需要调用 stmt.Exec(),而 stmt.Exec() 的参数依次对应 db.Prepare() 参数中 SQL 变量占位符 ?
- 由于 stmt.Exec() 返回值是一个 sql.Result 对象,所以在代码中直接调用 rs.LastInsertId() 来获取自增ID来判断是否增加数据成功
提示:返回的 LastInsertId 是int64位类型,可以通过 strconv.FormatInt(lastInsertID, 10) 来将其转换为字符串,其中第二个参数 10 代表十进制。
查询单条数据
// articlesShowHandler 文章详情.
func articlesShowHandler(w http.ResponseWriter, r *http.Request) {
// 1.获取 URL 参数
vars := mux.Vars(r)
id := vars["id"]
// 2.读取对应的文章数据
article := Article{}
query := "SELECT * FROM articles WHERE id = ?"
err := db.QueryRow(query, id).Scan(&article.ID, &article.Title, &article.Body)
// 3.如果出现错误
if err != nil {
// 判断是没找到数据 还是查询报错了
if err == sql.ErrNoRows {
w.WriteHeader(http.StatusNotFound)
fmt.Fprint(w, "文章未找到")
} else {
checkError(err)
w.WriteHeader(http.StatusInternalServerError)
fmt.Fprint(w, "500 服务器内部错误")
}
} else {
// 4.读取数据成功
tmpl, err := template.ParseFiles("resources/views/articles/show.gohtml")
checkError(err)
tmpl.Execute(w, article)
}
}代码都很简单,可以让人一目了然,但需要多注意db.QueryRow和Scan位置的使用。
查询多条数据
// articlesIndexHandler 文章列表.
func articlesIndexHandler(w http.ResponseWriter, r *http.Request) {
// 1.执行查询语句,返回一个结果集
rows, err := db.Query("SELECT * FROM articles")
checkError(err)
defer rows.Close()
// 2.循环读取结果
var articles []Article
for rows.Next() {
var article Article
// 2.1扫描每一行的结果并赋值到一个 article 对象中
err := rows.Scan(&article.ID, &article.Title, &article.Body)
checkError(err)
// 2.2将 article 追加到 articles 这个切片当中
articles = append(articles, article)
}
// 2.3检测遍历时是否发生错误
err = rows.Err()
checkError(err)
// 3.加载模板
tmpl, err := template.ParseFiles("resources/views/articles/index.gohtml")
checkError(err)
// 4.渲染模板,将所有文章的数据传输进去
tmpl.Execute(w, articles)
}释义参见如下:



评论前必须登录!
注册